
🔍 How to participate¶
Challenge execution and evaluation
Classification phase (opened, until 15th January 2024)
Next figure summarizes the steps for the execution of the classification phase:
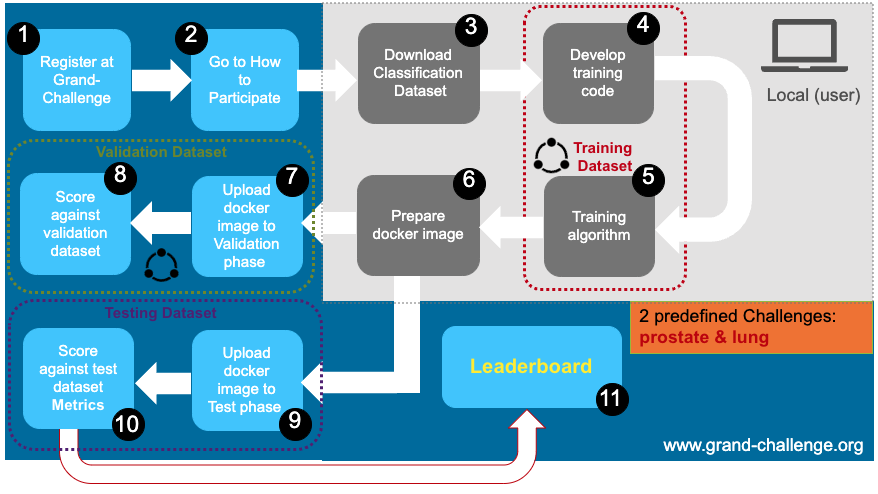
Every participant must sign up for a Grand-Challenge account (at www.grand-challenge.org), the account has to be verified (you can ask for verification on your profile) (1) and send the organizer (to chaimeleon@quibim.com), an e-mail requesting to participate in the Challenge and attaching a signed version of the Terms and Conditions, completed with all information requested.
After careful assessment, the organizer will notify the selected participants of their acceptance to participate in the Challenge and will send data access links to them. During this phase, participants will download a highly controlled training dataset for prostate and lung cancers (3).
The dataset is composed of a set of NIfTI (imaging data) and JSON files (clinical data) for both prostate and lung cancer. Participants will use this training dataset to develop their proposed AI models using their own resources (4,5). Once a model is ready to be evaluated, participants will prepare an inference container (6), this is a docker container that encapsulates a trained AI algorithm together with all the components needed to load and prepare a new case (image and clinical data) and generate the corresponding output.
The evaluation phase is split into two different phases:
-
Validation and tunning: participants can upload the prepared docker image to the “Validation phase” (7) and the corresponding metrics will be extracted using the validation dataset (8). The associated leaderboard will be updated. The number of applications on the validation dataset will be limited to 3 submissions.
-
Test: Once a final model is selected by the participants, they will upload the docker image to the “Test phase” (9) and the corresponding metrics will be extracted using the test dataset (10). The associated leaderboard will be updated. A single submission will be allowed in this face.
Finally, we will use the leaderboard from the test phase to select the top 40 participants that will continue in the Championship phase (11).
Championship phase (starting January 2024)
Next figure summarizes the steps for the execution of the classification
phase:

The selected participants will access the ChAImeleon platform to train their models on complete datasets for the five cancer types (1). Participants will define their strategy and participate in the challenge they select. ChAImeleon infrastructure will be used by participants to train their models (2), and each participant will have access to the same computational resources and computational time. In addition, participants will have access to harmonization solutions, developed by ChAImeleon consortium, that can be used during training.
Once an AI model is trained a ready for validation, participants will conduct the validation in two phases:
-
Validation and tunning: participants will execute their trained AI model over the validation dataset and generate a CSV file with the corresponding model outputs. This CSV will be uploaded to the “Validation phase” in grand-challenge platform (4). The number of applications on the validation dataset will be limited to 3 submissions per month.
-
Test: participants will execute their trained AI model over the test dataset and generate a CSV file with the corresponding model outputs. This CSV will be uploaded to the “Test phase” in grand-challenge platform (4). The number of applications on the validation dataset will be limited to a single submission during the whole phase.
Detailed information on the structure of these CSV files will be given at the beginning of the Championship phase.
Rules¶
-
This challenge only supports the submission of fully automated methods in Docker containers. It is not possible to submit semi-automated or interactive methods.
-
All Docker containers submitted to the challenge will not have access to the internet, and cannot download/upload any resources. All necessary resources must be encapsulated in the submitted containers.
-
Participants can use other pre-trained models and pre-processing algorithms (e.g., denoising, segmentation, etc.), however, these need to be publicly available.
-
Participants are not allowed to use external data. Only the data provided by the challenge organizers can be used.
-
To be awarded, participants need to submit a summary in PDF format of max. 300 words defining the methodology followed. An image with a graphical abstract will be appreciated. Additionally, a public/private URL to their source code on GitHub (hosted with a permissive license) will be required.
-
The winning algorithms in the Championship phase of each challenge (prostate, lung, breast, colon, and rectum) will be integrated into the ChAImeleon platform for their external validation.
-
Any publication resulting from the ChAImeleon Open Challenge should include the following reference:
Bonmatí LM, Miguel A, Suárez A, Aznar M, Beregi JP, Fournier L, Neri E, Laghi A, França M, Sardanelli F, Penzkofer T, Lambin P, Blanquer I, Menzel MI, Seymour K, Figueiras S, Krischak K, Martínez R, Mirsky Y, Yang G, Alberich-Bayarri Á. CHAIMELEON Project: Creation of a Pan-European Repository of Health Imaging Data for the Development of AI-Powered Cancer Management Tools. Front Oncol. 2022 Feb 24;12:742701. doi: 10.3389/fonc.2022.742701. PMID: 35280732; PMCID: PMC8913333.

The ChAImeleon project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 952172.
Privacy
The Chaimeleon Open Challenges complies with the strictest data privacy regulations and ethical standards.
Disclaimer
Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the granting authority can be held responsible for them.